You can use Sidekiq Enterprise with any number of apps and processes and machines as long as their total worker thread count in production is <= the licensed amount. Development and staging environments are free and unlimited.
https://github.com/mperham/sidekiq/wiki/Commercial-FAQ
Working directory of reg-suit. => .reg テストの結果を出力するディレクトリを指定します。デフォルトの.regディレクトリのままで問題ありません。
Append ".reg" entry to your .gitignore file. => Yes
reg-suitの出力結果はAWS s3で管理するので、Gitの管理下から外すためYesにします。
Directory contains actual images. => __screenshots__ テストに利用する画像のディレクトリを指定します。
Storycapのデフォルト値の__screenshots__を指定します。
Threshold, ranges from 0 to 1. Smaller value makes the comparison more sensitive. => 0 テストの差分比較の閾値を設定します。 厳密に差分検知をしたい場合は0を指定します。
notify-github plugin requires a client ID of reg-suit GitHub app. Open installation window in your browser => Yes
GitHub Appのreg-suitの登録を行います。
reg-suitの設定ページがブラウザで開くので、ビジュアルリグレッションを導入したいリポジトリを選択します。
Client IDをクリップボードにコピーしておきます。
This repositoriy's client ID of reg-suit GitHub app => {Client ID}
GitHub AppのページでコピーしたClient IDを設定します。
Create a new S3 bucket => No
AWSにログイン済みでs3の作成権限があればYesにしてbucketの作成を行います。 権限がなかったので今回はNoで回答しました。
Existing bucket name => ***
s3のBucketが作成済みの場合、ここでbucket名を設定します。
structMeal:Codable {
letid:IDlettime:Dateletcategory:MealCategoryletstyle:MealStylevarcontent:String?
varmemo:String?
letcreatedAt:DateletupdatedAt:Datevarphotos:[Photo]varmealTags:[MealTag]structID:Identifiable {
letrawValue:Int
}
enumCodingKeys:String, CodingKey {
case id
case time
case category ="categoryCode"case style ="styleCode"case content
case memo
case createdAt
case updatedAt
case photos
case mealTags
}
}
ruby-vipsは、画像処理ライブラリであるlibvipsのRubyバインディングになります。
こちらのGemを利用することで、Ruby on RailsのWebアプリケーションに画像処理の機能を追加することができます。
実際にruby-vipsの導入方法や、簡単な使い方は下記スライドにて紹介しておりますので、ご参照いただければと思います。
2015年の開発当時は Go 1.5 を使っていたため、入社時点で開発環境として支給された macOS Mojave ではコンパイルしたバイナリを実行すると実行バイナリの応答が無い状態になり、30分程待っても何も起らず正しくコンパイルできてない事が判明しました。(本番への deploy 環境は Linux なので問題なし。)
Go のコンパイラのバージョンを変えいくつか試したところ macOS 10.12 Sierra 以降では go 1.7以上必須である事がわかったため、Go のバージョンを当時の最新の 1.13 まで上げ、かつ、struct 周りの記述ミスでコンパイルエラーが発生していたのを修正する事で開発環境のmacOS Mojaveで無事動作するようになりました。
CIが停止していたので、動くようにする。
2015年の開発当時は社内の Circle CI 1.0 (Enterprise) で CIが動作していたようなのですが、社内開発環境のクラウド移行時に、メンテナー不在の影響でクラウド環境のCircle CI 2.0 移行が行われずCIが停止していました。
Circle CI 1.0 当時の設定が残っていたので、Circle CI 2.0 で動作するように対応を行い、カバレッジ情報の出力を追加するなどCI環境を整備しました。
前職は組み込み系のテストプログラム開発を行なっていたため Go は触った事がなかったのですが、Go は言語仕様が比較的小さいため2週間程の勉強は必要でしたが無事改善が回せております。
開発分野が前職とはだいぶ異なるため新たに学ぶ事が多いですが、(Goに限らず)日々新しい事に取り組みつつ楽しく開発をしております。
case ["a", 1, "b", "c", 2, "d", "e", "f", 3]
in [*pre, String => x, String => y, *post]
p pre #=> ["a", 1]
p x #=> "b"
p y #=> "c"
p post #=> [2, "d", "e", "f", 3]end
irb(main):001:0> {b: 0, c: 1} => {b:}
(irb):1: warning: One-line pattern matching is experimental, and the behavior may change in future versions of Ruby!
irb(main):001:1* case ["a", 1, "b", "c", 2, "d", "e", "f", 3]
irb(main):002:1* in [*pre, String => x, String => y, *post]
irb(main):003:1* p x #=> "b"
irb(main):004:0> end
(irb):2: warning: Find pattern is experimental, and the behavior may change in future versions of Ruby!
"b"
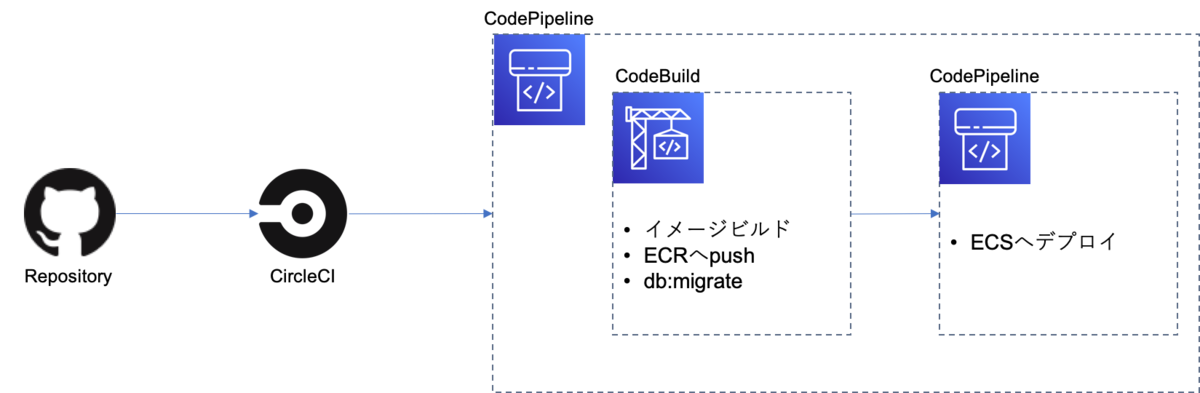
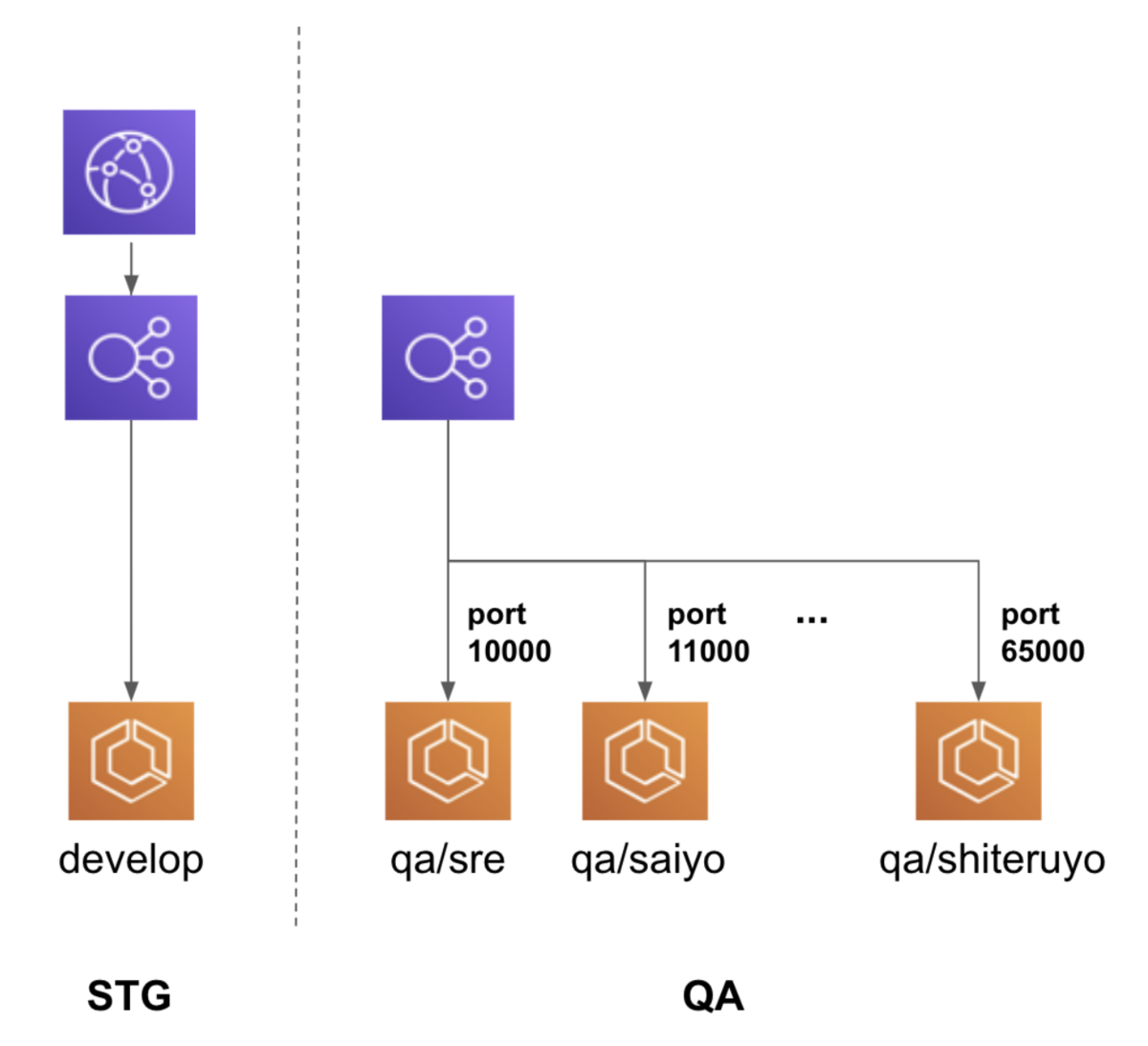
① ブランチ qa/fooを push ② CircleCI 実行 ③ CodePipeline 作成 or 実行 ④ Rails イメージビルドし ECR へ push ⑤ TargetGroup, Listner を 既存 STG 環境 LB に追加 ⑥ ECS Service 作成 or 更新を実行
ブランチ qa/fooに push すると ECS Service を作成・更新する、
という仕組みです。*2
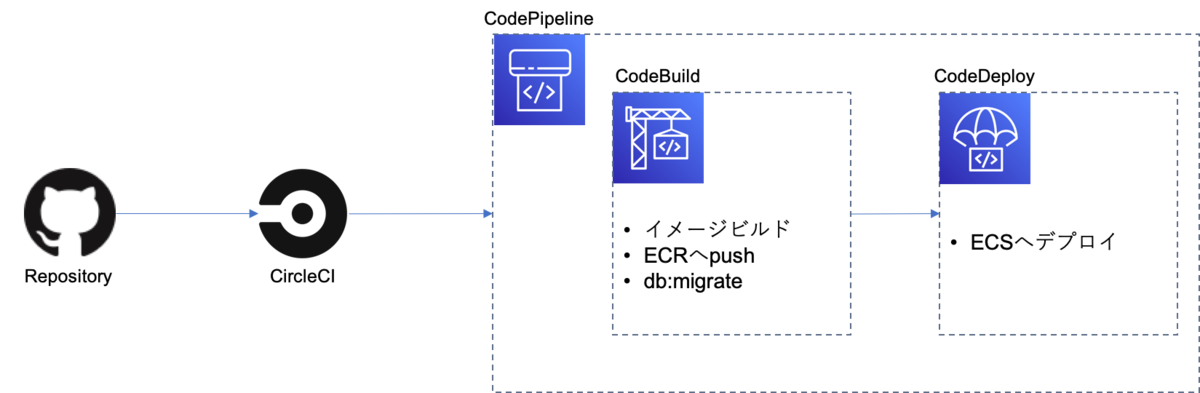
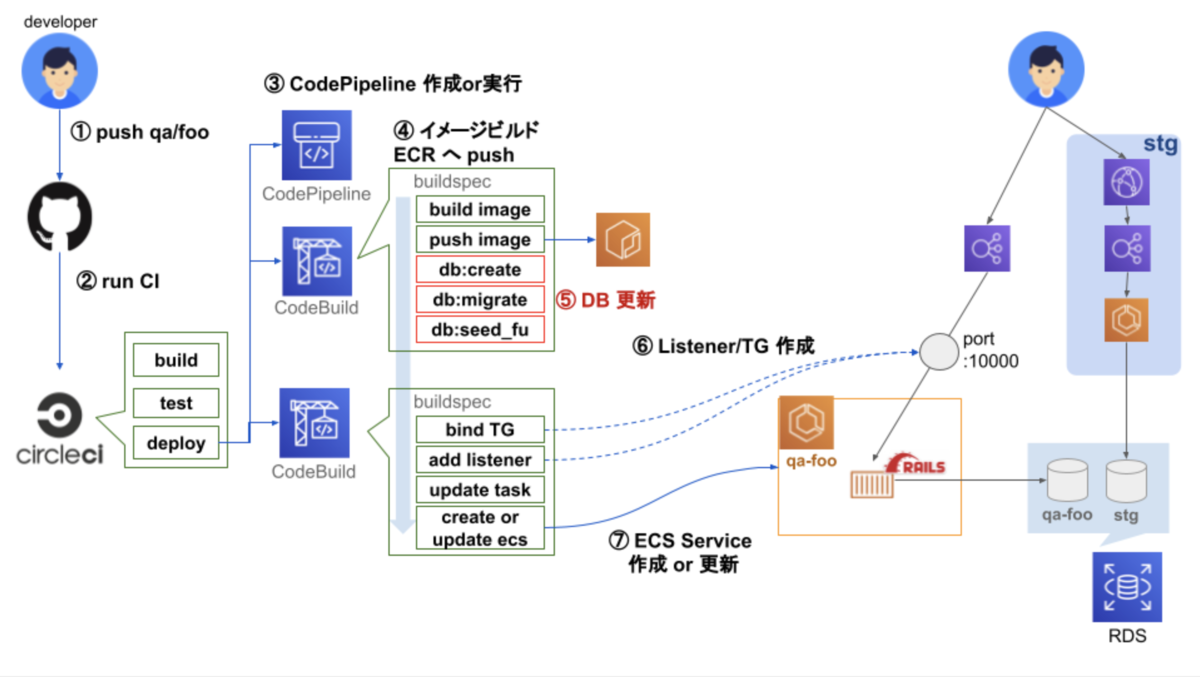
最新の仕組み
大まかな流れ
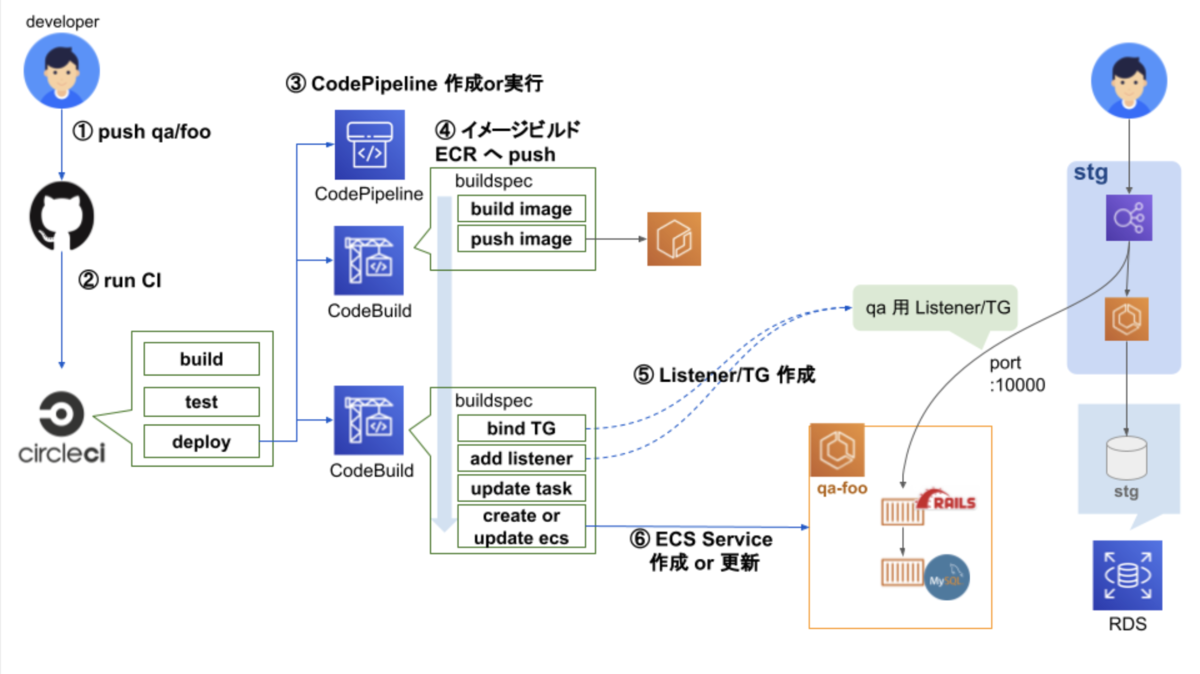
① ブランチ qa/fooを push ② CircleCI 実行 ③ CodePipeline 作成 or 実行 ④ Rails イメージビルドし ECR へ push ⑤ DB 更新 ⑥ TargetGroup, Listner を QA 環境用 LB に追加 ⑦ ECS Service 作成 or 更新を実行
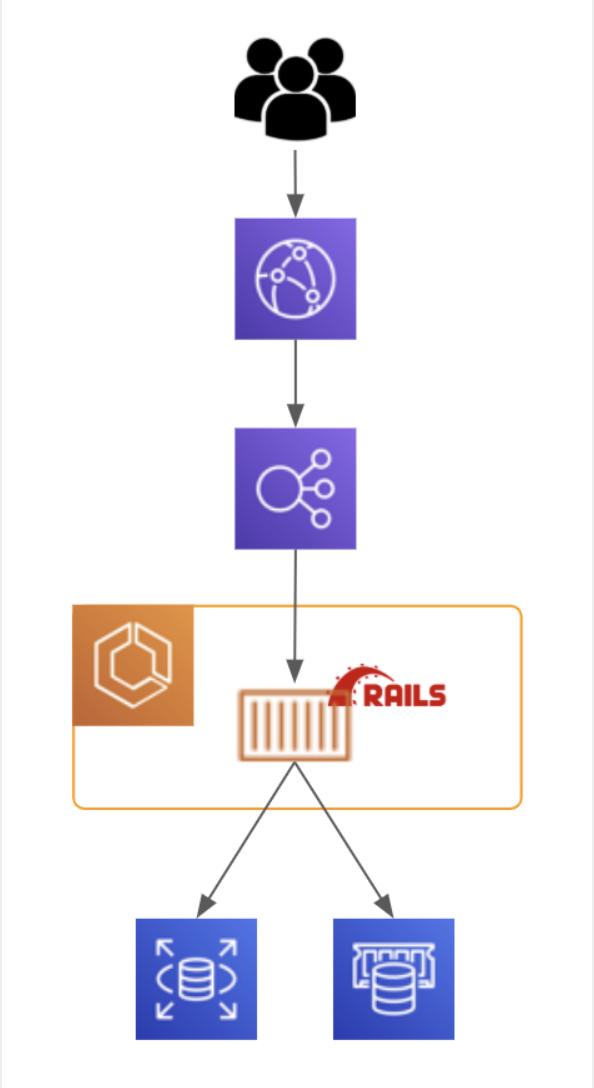
当時と最新の検証環境の自動構築の仕組みの違い
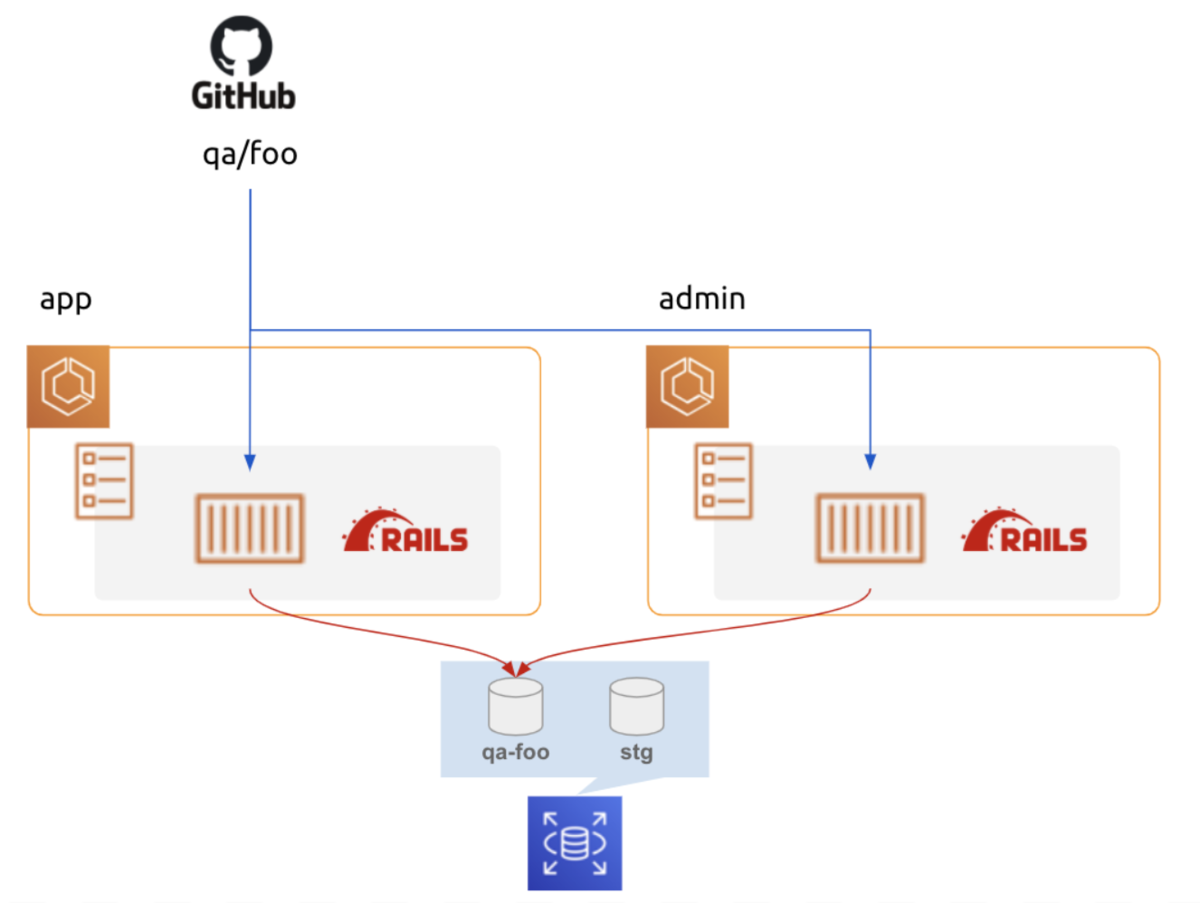
QA 環境用の LB を用意
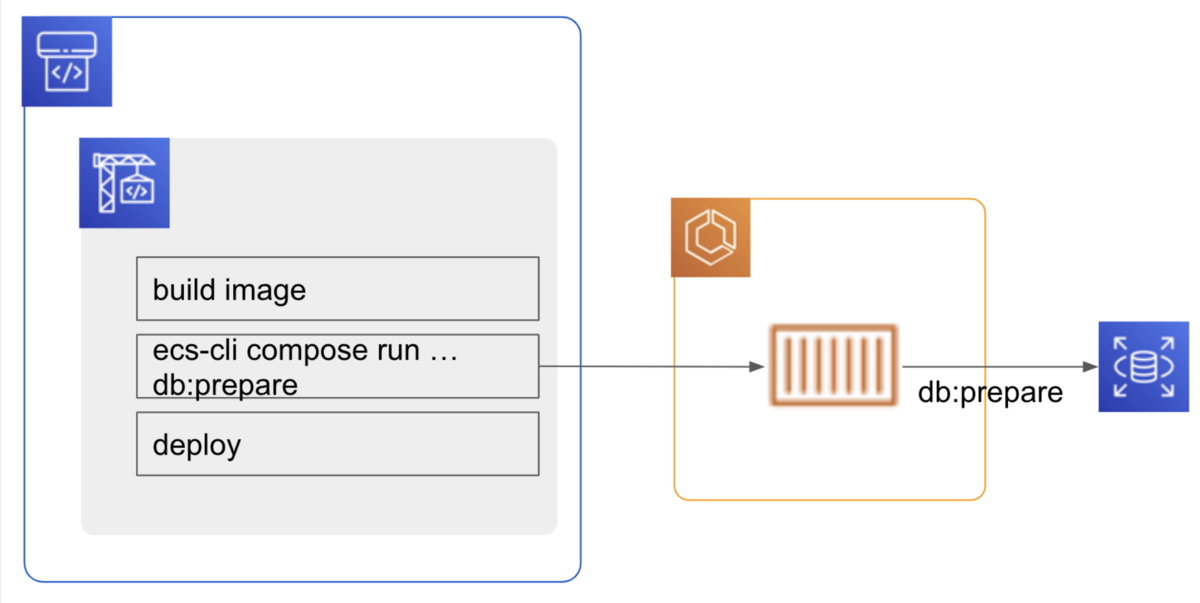
CodeBuild 内で DB 更新
既存 STG DB に QA 環境用 スキーマ作成
この様な仕組みへと変わった歴史を見ていきたいと思います。
構築当初の問題と解決の歴史
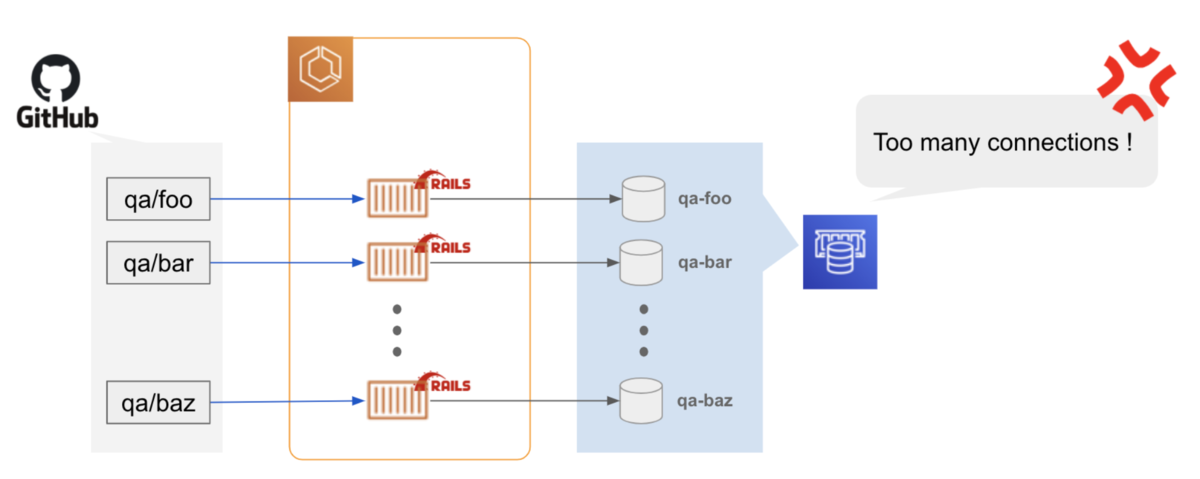
問題1: デプロイする度に DB データが初期化される
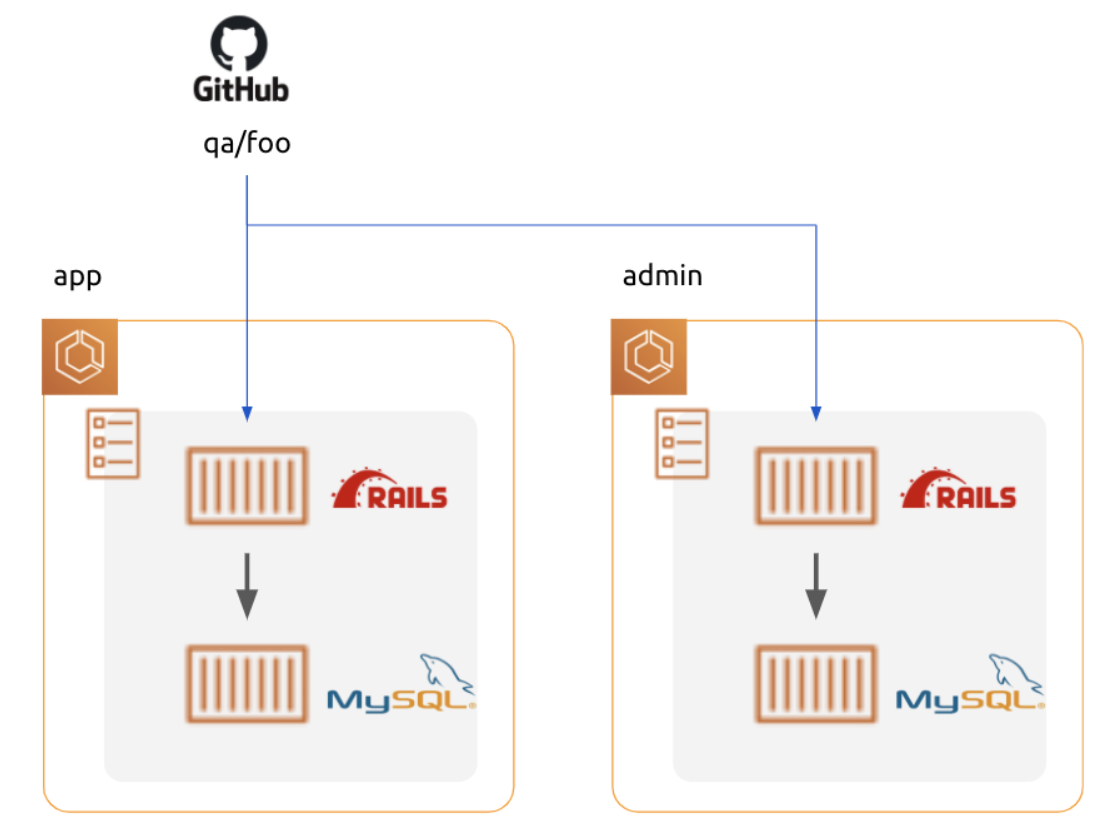
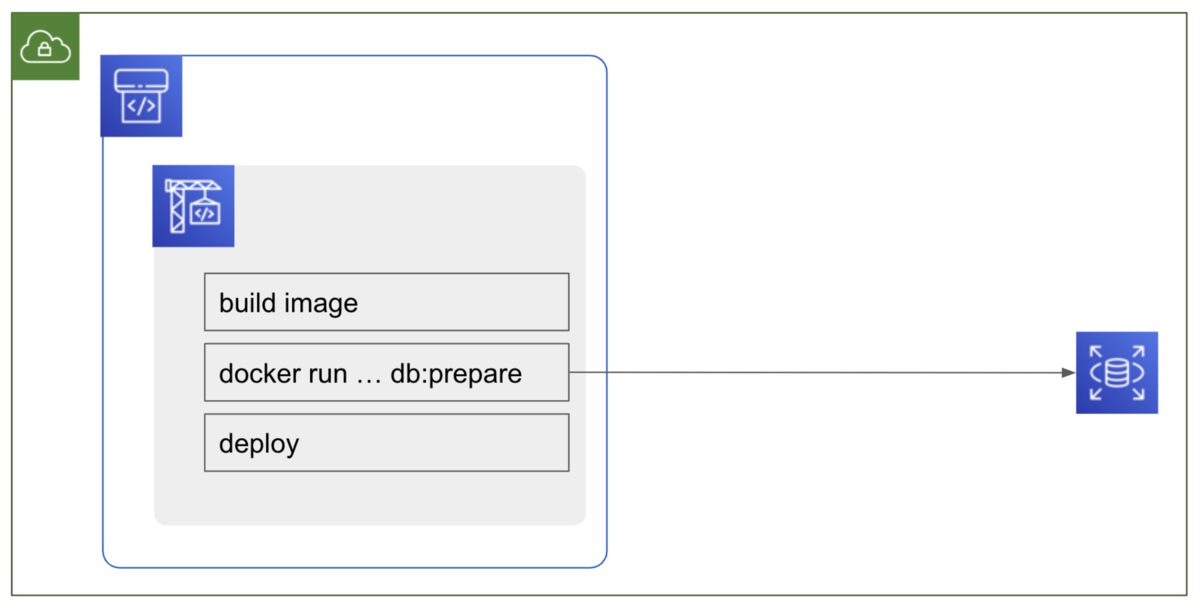
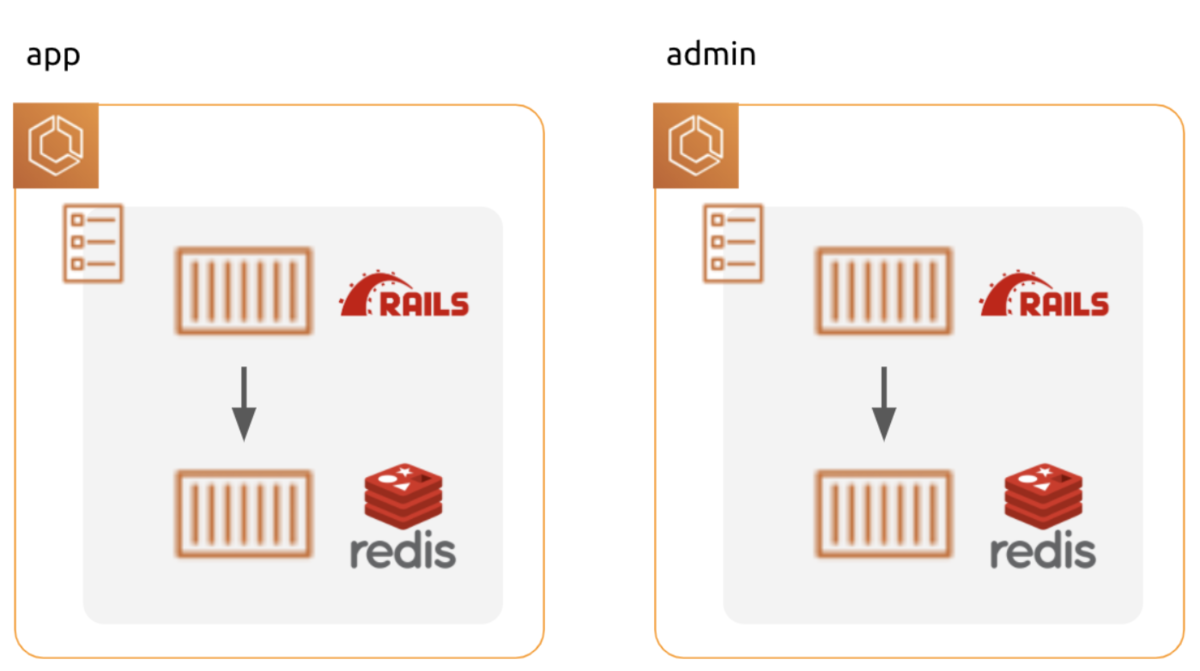
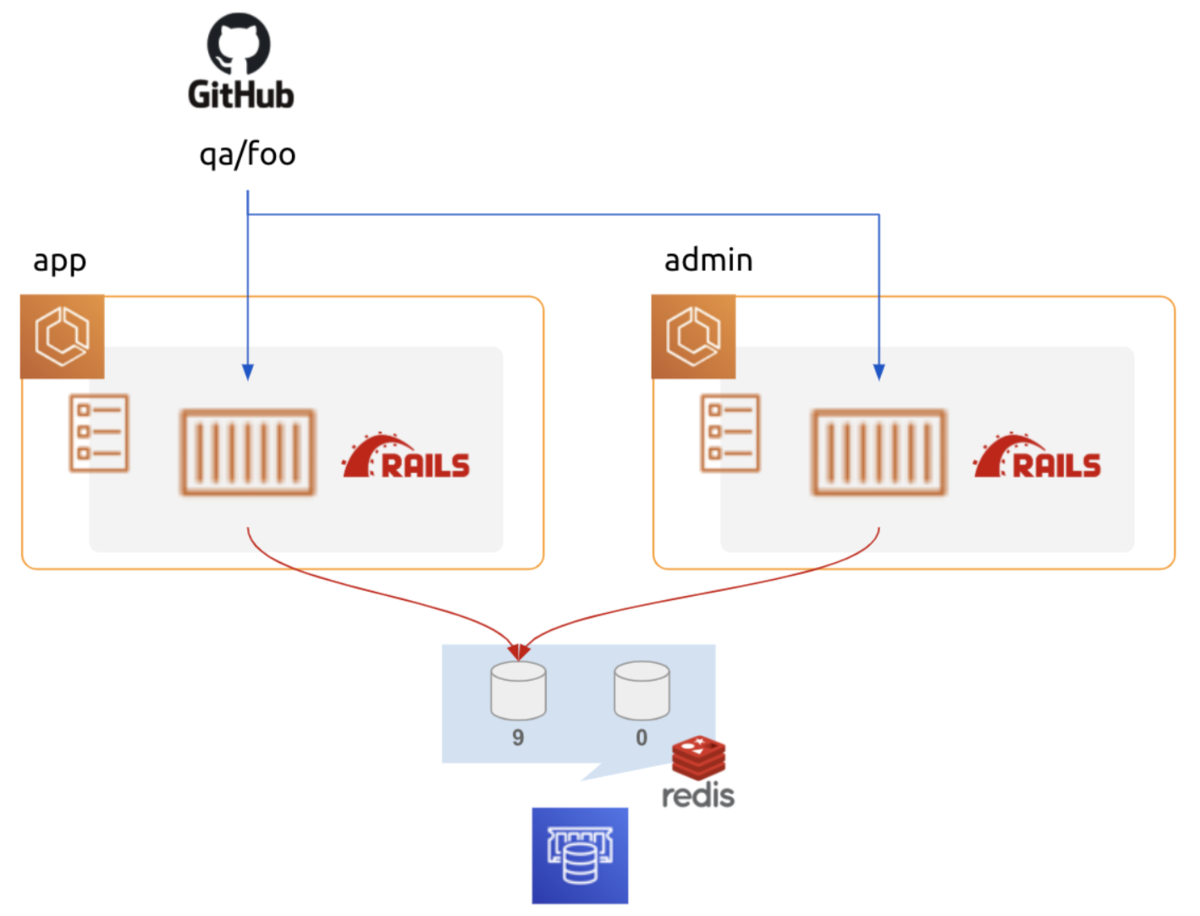
当初、 QA 環境は上図の構成を取っていました。
role (app, admin) 毎に別々にタスク内にDB コンテナを起動し、参照しています。
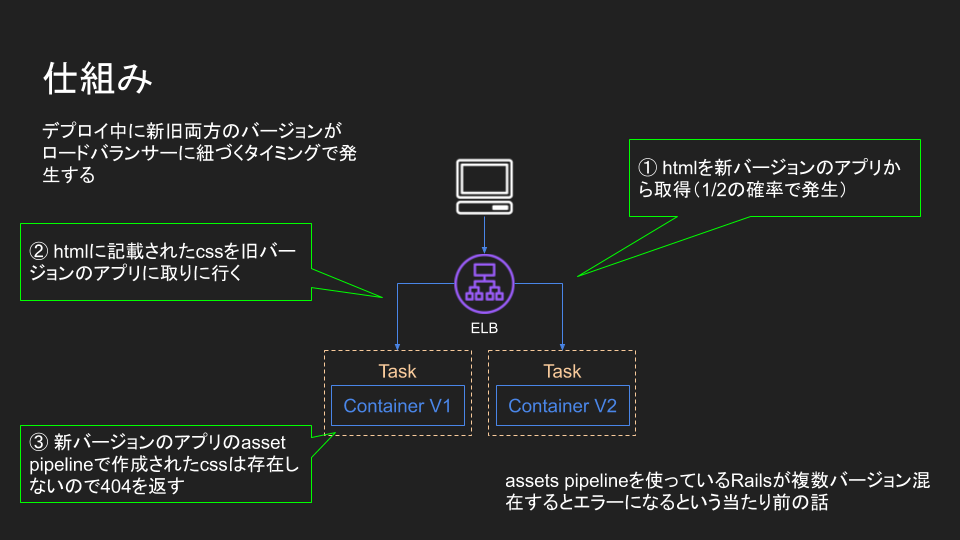
DB コンテナはデータを永続化していません。 デプロイ毎にデータが初期化されてしまいます 😢
もう一つ問題があります。
app と admin で共通の DB を見ていない為、app で更新したデータを admin で参照できません。
> [bundle 2/2] RUN bundle install && rm -rf vendor/bundle/ruby/3.0.1/cache/*:
#12 0.953 Your bundle only supports platforms ["x86_64-darwin-20"] but your local platform
#12 0.953 is x86_64-linux-musl. Add the current platform to the lockfile with `bundle lock
#12 0.953 --add-platform x86_64-linux-musl` and try again.